Computer ergonomics II – xterms colors
After the basic setup for the xterms colors are very important. My personal theory is that always looking at the same color tires the eyes. To avoid that I use some scripts to randomize the colors based on some basic patterns.
First I have the blackterm. This is a white on black setup, but with the white and black actually being randomized shades of grey. This way all the xterms look slightly different and can be easily visually distingushed. blackterm is my basic terminal that I’ve used for a long time.
Then I got the whiteterm. According to conventional wisdom black on white is easier to handle for the brain, although I am never sure I ever quite believed it. But still it’s useful I guess. whiteterm works the same way as blackterm and actually uses shades of grey, just the white and black are switched.
I typically try to combine both the black terms and the white terms in a single desktop, with giving priority to one of them depending on mood.
Then the final piece is the randterm. The idea and data file is originally from David Holland. randterm randomizes the foreground and background colors based on a data file. Some of the combinations are not so great (but I already eliminated most of the really awful ones), but most are ok. Sometimes when I don’t like a combination I start it a few times until I get one that matches my current mood. Typically I add one or two randterms to the stable of black and white terminals to make the desktop more visually interesting.
For all of those I have large (18 pixels) and small (10 pixels) variants. The scripts default to large and can be switched to small with the --small argument.
Overall in a desktop menu you end up with 6 choices to create your xterm menu or shortcuts:
| Color | Large | Small |
| Black-on-White | blackterm |
blackterm --small |
| White-on-Black | whiteterm |
whiteterm --small |
| Random | randterm |
randterm --small |
With these choices you can set up a colorfull desktop that is easy on the eyes, like this:
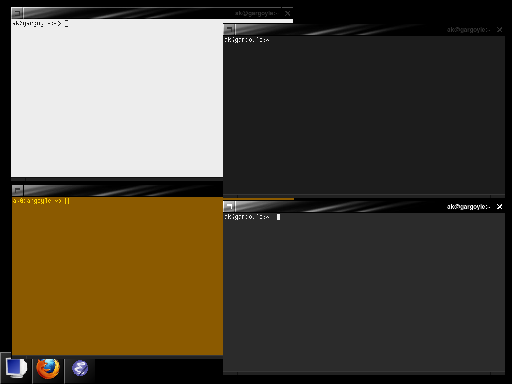
The same idea can be applied to other programs. I used to do the same with Emacs windows, although currently I went back to mostly plain black on white Emacs.
One problem with the different schemes are terminal programs that use their own color schemes, like vim or lynx or emacs -nw. They typically have color schemes for dark or light xterms that you can statically configure, but do not really deal well with having both dark and light and even randomized. Often I just turn off the colors. An easy way to do that is to start them with TERM=vt100 … The programs often fall back to using bold instead of colors then, which works for me.
At least for vim I tended to also have aliases to start vim with a dark color set and a light color set, but you always have to remember to use the right alias then and it doesn’t quite work with programs that start the editor directly through $EDITOR. So usually I just turn them off or rely on bold only.
I guess best would be wrappers that query the xterm on their current colors and select the right color schemes, but I haven’t implemented that so far.
Computer ergonomics I – xterms fonts
If you do your computer work mostly in text terminal windows like me, setting up the right ergonomics for them is very important. It always pays off to invest some time in setting up the environment you spend the most time in (like you should spend some resources on finding the right mattress you spend one third of your live on)
First I use good old xterm(1). xterm is much faster than the default terminals now used in desktops. Gnome Terminal has lots of problems: First it is quite slow, which can make a big difference for jobs that generate a lot of output like a large compilation (see the warning from the SBCL folks at the bottom of the page). And it does have strange semantics with cut-n-paste. And various other issues. I haven’t used the KDE terminal program for some time, but I remember it also being somewhat problematic. On the other hand xterm just works. xterm tends to be included with distributions, but on some newer versions you need to install the package explicitely.
The defaults of xterm are quite reasonable, except for the too small scrollback buffer. The later can be set with the -sl option or by putting a XTerm*saveLines: line into your .Xdefaults. I usually also disable the scrollbar with +sb to disable clutter.
Then you need a good font for them. The default fonts used in xterms are not great and tend to be too small at least for me. The best xterm font I know of is the sgi-screen font. This is a bitmap font that has been properly designed by a good font designer, not TTF. If you ever used an SGI IRIX workstation that’s the font used in the text terminals. Luckily SGI freed it some time ago and the font is included with OpenSUSE. The rpm installs fine on other distributions (with –nodeps), but you may need to set up the font path manually. For example in Fedora this can be done with ln -s /usr/share/fonts/misc/sgi/ /etc/X11/fontpath.d

One trap with xterms is that if you set the font using the -fn argument xterm will automatically try to generate an bold font for it. sgi-screen has bold versions of each font, but xterm cannot find it directly for some reason. I work around this by always specifying a bold font too (with -fb)
Setting the right font size is important too. I tend to use large and small xterms for different purposes. For a primary work xterm you want a larger font (I use the 18 pixels sgi-screen usually). To watch a logfile or nurse a long running compile job I use a smaller font, like a 10 pixel sgi-screen.
Setting the right size is also important. Typesetters know that too long lines are hard to read. Because of that I try to avoid xterms beyond 80 characters width.
More on xterms later.
Update: fixed link to sgi-fonts.
The Korean Tamagotchi
My Samsung mobile dumb phone has the annoying tendency to complain in the middle of the night when it runs out of battery. For some reason this always happens in the middle of the night and already has woken me up several times. The alarm happens multiple times, so if you don’t give it its juice on time it’ll wake you up later again. It’s a bit like a small kid or a Tamagotchi (are they actually still used?).
It’s very annoying. It’s interesting to think how to designers could have avoided the problem. Check the current time zone and do battery alarms in a few hours in advance during normal waking hours?
Big kernel lock semantics
My previous post on BKL removal received some comments about confusing and problematic semantics of the big kernel log. Does the BKL really have weird semantics?
Again some historical background: the original Unix and Linux kernels were written for single processor systems. They employed a very simple model to avoid races accessing data structures in the kernel. Each process running in kernel code owns the CPU until it yields explicitly (I ignore interrupts here, which complicate the model again, but are not substantial to the discussion). That’s a classical cooperative multi-tasking or coroutine model. It worked very well, after all both Unix and Linux were very successful.
Coroutines are a established programming model: in many scripting languages they are used to implement iterators or generators. They are also used for lots of other purposes, with many libraries being available to implement them for C.
Later when Linux (and Unix) were ported to multi-processor systems this model was changed and replaced with explicit locks. In order to convert the whole kernel step by step the big kernel lock was introduced which emulates the old cooperative multi-tasking model for code running under it. Only a single process can take the big kernel lock at a time, but it is automatically dropped when the process sleeps and reaquired when it wakes up again.
So essentially BKL semantics are not “weird”: they are just classic Unix/Linux semantics.
Good literature on the topic is the older Unix Systems for Modern Architectures book by Curt Schimmel, which provides a survey of the various locking schemes to convert a single processor kernel into a SMP system.
When a subsystem is converted from the BKL it is often replaced by a mutex code lock. A single mutex protects the complete subsystem. This locking model is not fully equivalent with the BKL: the BKL is dropped when code sleeps, while the mutex will continue serializing even over the sleep region. Often this doesn’t matter: a lot of common kernel utility functions may sleep, but in practice do only rarely in exceptional cases. But sometimes sleeping is actually common — for example when doing disk IO — and in this case the straight forward mutex conversion can seriously limit parallelism. The old BKL code was able to run the sleeping regions in parallel. The mutex version is not. For example I believe this was a performance regression in the early versions of Frederic Weisbecker’s heroic reiserfs BKL conversion.
With all this I don’t want to say that removing the BKL is bad: I actually did some own work on this and it’s generally a good thing. But it does not necessarily give you immediate advantages and may even result in slower code at first.
Removing the big kernel lock. A big deal?
There’s a lot of hubbub recently about removing the big kernel lock completely in Linux 2.6.37. That is it’s now possible to compile a configuration without any BKL use. There is still some code depending on the BKL,
but it can be compiled out. But is that a big deal?
First some background: Linux 2.0 was originally ported to SMP the complete kernel ran under a single lock, to preserve the same semantics for kernel code as on uni-processor kernels. This was known as the big kernel lock.
Then over time more and more code was moved out of the lock (see chapter 6 in LK09 Scalability paper for more details)
In Linux 2.6 kernels very few subsystems actually still rely on the BKL. And most code that uses it is not time critical.
The biggest (moderately critical) users were a few file systems like reiserfs and NFS. The kernel lockf()/F_SETFL file locking subsystem was also still using the BKL. And the biggest user (in terms of amount of code) were the ioctl callbacks in drivers. While there are a lot of them (most drivers have ioctls) the number of cycles spent in them tends
to be rather minimal. Usually ioctls are just used for initialization and other comparatively rare jobs.
In most cases these do not really suffer from global locking.
This is not to say that the BKL does not matter at all. If you’re a heavy parallel user of a subsystem or a function that still needs it then it may have been a bottleneck. In some situations — like hard rt kernels — where locking is more expensive it may also hurt more. But I suspect for most workloads this wasn’t already the case for a long time,
because BKL is already rare and has been eliminated from most hot paths a long time ago.
There’s an old rule of thumb that 90% of all program run time is spent in 10% of code (I suspect the numbers are actually even more extreme for typical kernel loads). And that should only tune the 10% that matter and leave the rest of the code alone. The BKL is likely already not in your 10% (unless you’re unlucky). The goal of kernel scalability is to make those 10% run in parallel on multiple cores.
Now what happens when the BKL is removed from a subsystem? Normally the subsystem gains a code lock as the first stage: that is a private lock that serializes the code paths of the subsystem. Now using code locks is usually considered
bad practice (“lock data, not code”). Next come object locks (“lock data”) and then sometimes read-copy-update and other fancy lock-less tricks. A lot of code gets stuck in the first or second stages of code or coarse-grained data locking.
Consider a workload that tasks a particular subsystem in a highly parallel manner. The subsystem is most
of the 90% of kernel runtime. The subsystem was using the BKL and gets converted to a subsystem code lock.
Previously the parallelism was limited by the BKL. Now it’s limited by the subsystem code lock. If you don’t have
other hot subsystems that also use the BKL you gain absolutely nothing: the serialization of your 90% runtime is still there, just shifted to another lock. You would only gain if there’s another heavy BKL user too in your workload, which is unlikely.
Essentially with code locks you don’t have a single big kernel lock anymore, but instead lots of little BKLs.
As a next step the subsystem may converted to more finegrained data locking. For examples if the subsystem has a hash table to look up objects and do something with them (that’s a common kernel code pattern) you may have locks per hash bucket and another lock for each object. Objects can be lots of things: devices, mount points, inodes,
directories, etc.
But here’s a common case: your workload only uses one object (for example all writes to the same SCSI disk) and that code is the 90% runtime code. Now again your workload will hit that object lock all the time and it will limit parallelism.
The lock holding time may be slightly smaller, but the fundamental scaling costs of locking are still there. Essentially you will have another small BKL for that workload that limits parallelism.
The good news is that in this case you can at least do somethingabout it as kernel user: you could change the workloads to spread the accesses out to different objects: for example use different directories or different devices. In some cases that’s practical, in others not. If it’s not you still have the same problem. But it’s already a large step in the right
direction.
Now a lot of the BKL conversions recently were simply code locks. About those I must admit I’m not really excited.
Essentially a code lock is not that much better as the BKL. What’s good is data locking and other techniques. There
are a few projects that do this like Nick Piggin’s work on VFS layer scalability, Jens Axboe’s work on block layer scalability, the work on speculative page fault and lots of others. I think those will have much more impact on real kernel scalability than the BKL removal.
So what’s left: The final BKL removal isn’t really a big step forward for Linux. It’s more a symbolic gesture, but I prefer to leave those to politicians and priests.
The 2.6.35.10 longterm Linux kernel has been released
2.6.35.10 is out. Since it contains security fixes all 2.6.35 users are encouraged to update. Get it at
ftp://ftp.kernel.org/pub/linux/kernel/v2.6/longterm/v2.6.35/ or from git://git.kernel.org/pub/scm/linux/kernel/git/longterm/linux-2.6.35.y.git Full release notes.
Thanks to all contributors and patch reviewers.
Linux kernel 2.6.35 longterm maintenance
After Greg Kroah-Hartmann stopped maintaining 2.6.35-stable. I plan to maintain the 2.6.35 linux kernel tree longterm for now. Thanks to Greg for all his hard work on this.
The primary consumers of 2.6.35 right now are Meego and the CE Linux Forum, but some others are interested and everyone who wants a long term stable tree is of course free to use it.
The longterm tree continues after Greg’s 2.6.35.9 stable release. It will not be called “stable”, but called “longterm” to make the distinction clear.
longterm has no defined end date (but also no guarantee that it will be around forever) and will be maintained longer than normal stable kernels. The existing 2.6.32 stable kernel mainteind by Greg will be also named “longterm” now. There is also a 2.6.34 longterm kernel maintained by Paul Gortmaker.
The longterm kernels will move into new directories on kernel.org. The 2.6.35 releases will be available at ftp://ftp.kernel.org/pub/linux/kernel/v2.6/longterm/v2.6.35/. The other longterm kernels (.32 and .34) will get similar directories. The git tree for the release is available in git://git.kernel.org/pub/scm/linux/kernel/git/longterm/linux-2.6.35.y.git
The 2.6.35 longterm tree follows the stable rules in Documentation/stable_kernel_rules.txt
My plan is to look at all patches that go into later stables (that is which are sent to stable@kernel.org or marked Cc: stable@kernel.org in the git description) and merge them into 2.6.35 when applicable. I don’t expect there will be many
patches only for 2.6.35 and not for later stable trees. If there are and they are submitted to stable@kernel.org I will consider them. I plan to be fairly conservative.
I will follow a similar flow as Greg: There will be candidate trees which are posted to Linux kernel and have a 48h review period, with patches being dropped then as needed. Then the candidates will turn into releases, if noone objects to the patches.
The current candidate is 2.6.35.10-rc1. This will soon turn into 2.6.35.10.
The patches before a release are maintained in a quilt queue, which is available in a git repository at kernel.org. After that they migrate to the 2.6.35.y git tree.
Dependencies
Chris Wilson pointed me to a fix for the xterm font rendering problems I’ve been seeing on my Intel graphics laptop with Fedora 14. The fonts on each new xterm are corrupted until I resize it. I first blamed the Intel X driver (there were other xterm fixes in the past), but according to Chris it’s a compiz problem.
Anyways now I wanted to rebuild compiz-core to include the patch and see if it helps. First it took some time to figure out how to install source rpms with yum (summary: yum doesn’t support it; I guess I’m spoiled from zypper). Then
I ask yum to install all the -devel rpms which are dependencies for compiz-core’s source rpm. I got a full screen full of dependencies, culminating in yum asking me to install mysql-server. Yes, mysql-server to build a simple source rpm.
I guess it was taken in through some other dependencies, but installing a full database server for building some rpm is just crazy. I balked at that.
I guess I need to find now a script similar to SUSE’s build that builds in chroot or build it in build service
Fedora is not the only distribution with dependency hell. Some years ago I found out that one openSUSE released had a dependency from fvwm2 to gnome-print (which pulled in a lot of the rest of gnome)
Update: Fedora fixed this now with an update (see bug 614542) I’m really glad that the feels like 10 GB updates every day actually contain at least one valuable fix.
GUI design principle
Asking for a root password in response to someone pressing the power button on the machine
shows: the designer didn’t understand the problem to solve at all.
It told me that I need to enter the root password because someone else was logged in. That’s fine, but *I* can pull the power anyways.
The question is just: are the GUI designers or the security designers to blame.
(observed on Fedora 13)
Bloat
This is the recently announced “first usable” distribution of perl6 aka rakudo star. Just out of curiosity I compiled it for x86_64-linux using gcc 4.5.
Interesting results:
% size /usr/bin/perl5.12.1
text data bss dec hex filename
2778082 13076 584 2791742 2a993e /usr/bin/perl5.12.1
% size ~/src2/rakudo-star-2010.07/install/bin/perl6
text data bss dec hex filename
27972225 792 16 27973033 1aad5a9 rakudo-star-2010.07/install/bin/perl6
The text segment of perl6 is more than 10 times as big as that of perl 5.
Is it also 10 times as good?
That is progress I guess.